Sanskrit word embeddings
There are economic incentives to automate processing of global languages like English. Keeping the greenery aside, sometimes it is a good exercise to appreciate our culture, in this case the fascinating evolution of languages over generations. An interesting case study is the ancient language Sanskrit, that is still used today, and that is the mother of many other mainstream Indian languages. Using the advances in the field of computational linguistics, we explore a corpus of the Sanskrit language.
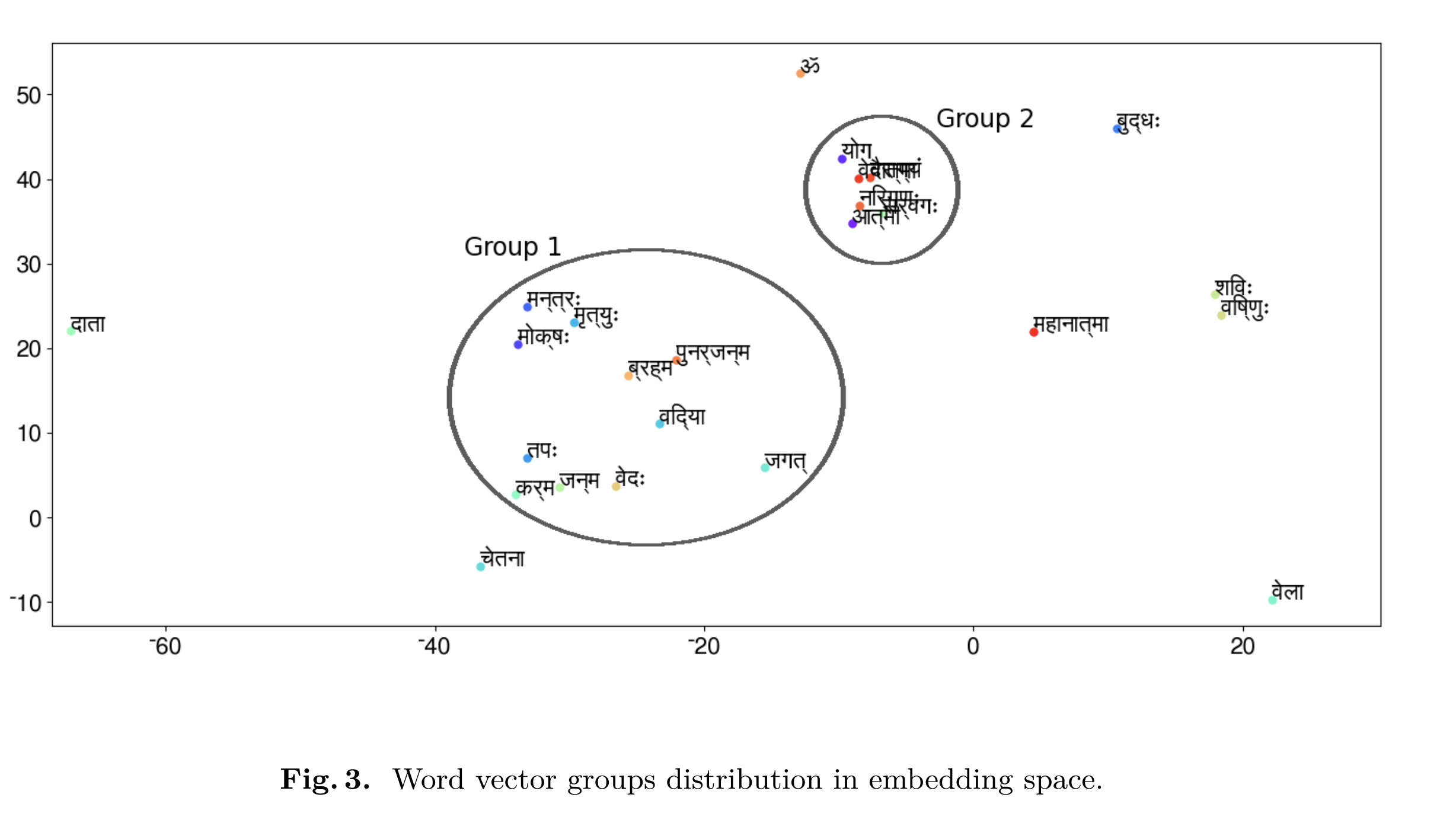
In this study, we parsed words in Sanskrit literature and found their vector embeddings. Then, we applied dimensionality reduction algorithms like t-SNE and PCA to visualize relations between vectors in the embedding space. We found that the vectors for similar words occupied the same region in the space. They follow compositionality as well, i.e., vector for mother + father - daughter is close to that of the son. This type of analysis can be used to understand the huge wealth of wisdom buried in the text of regional languages.
Reading characters of another language and understanding them was an engaging experience. Some of the examples in the compositionality section were quite surprising and we decided to publish them in a conference. I hope this work inspires others to take up projects with other regional languages.

{kind=link}